# Happy_LLM_08 LLM与PLM的区别?LLM是如何训出来的
# 第四章 大语言模型
(这是笔者自己的学习记录,仅供参考,愿 LLM 越来越好❤)由于篇幅较长,本篇会先讲如何做LLM的第一个阶段预训练,下一篇会讲后面的两个阶段
---
## 初识LLM
LLM = Large Language Model = 大语言模型
就是**训练数据**T级别、**参数**百亿10B+都很大,在**多卡**分布集群训出来的语言模型,也正因此让模型一下子超神了(涌现能力:语言能力一下子远超传统的PLM)
所以回答标题问题,和PLM的区别就是,LLM更大了,训练范式从预训练+微调,LLM的训练见下文
---
## 训一个LLM的步骤
主要有3个阶段:
- Pretrain 预训练
- SFT 监督微调
- RLHF 人类反馈强化学习
接下来看下每个阶段的难点
---
### 阶段1:Pretrain
> ps:这里就是和之前章节介绍过的PLM差不多,都是训练一个模型出来,因为后面还要继续对这个模型进行调整修改,所以这一阶段的模型叫做预训练模型,阶段叫预训练。很直观了。
预训练阶段,采用的架构是类GPT的decoder-only架构,任务是CLM。
---
#### 一些模型训练参数对比
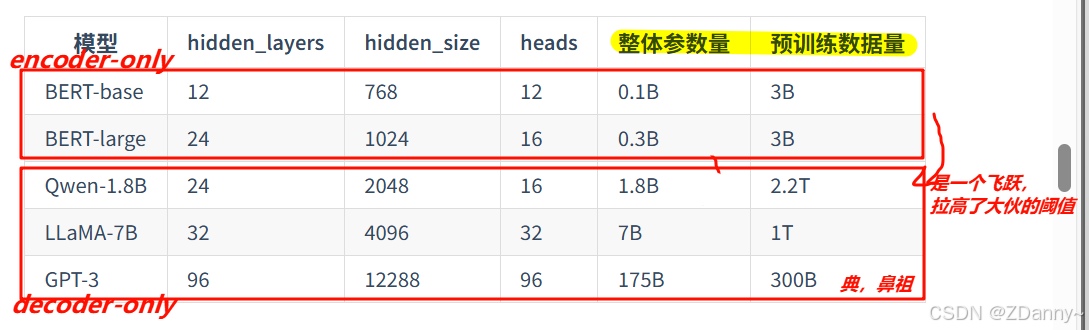
---
#### LLM 参数量和训练数据的爱恨情仇
指的是参数量和训练语料量的经验规律
`Scaling Law`(OpenAI):
$$C(计算量) \sim 6N(参数量)D(token数)$$实验得出:
`参数与数据的关系(最基本)`(OpenAI)
$$D(数据量) = 1.7N(参数量)$$
`参数与数据(性能最优)`(LLaMA)
$$D(数据量) = 20N(参数量),
$$
| 提出方 | 含义 | 举例(175B 参数) |
|--------|------|-------------------|
| **OpenAI** | 数据量与参数量近似成正比(训练资源平衡的基本经验) | $175B \times 1.7 \approx 297.5B$ tokens(GPT-3 实际用了约 300B) |
| **LLaMA (DeepMind 的 Chinchilla 研究)** | 在计算资源固定下,**最优性能**需要更多数据,约为参数量的 20 倍 | $175B \times 20 = 3500B = 3.5T$ tokens |
---
#### LLM的数据来源、处理和使用
模型会的基本来源于训练材料,所以材料很重要。
训练用数据 =
【开源语料】(CommonCrawl、C4、Github、Wikipedia 等、昆仑天工开源的SkyPile(150B)、中科闻歌开源的yayi2(100B)英文多中文少)
+
【自己的高质量数据】**(`配比和数据内容`都很重要)**
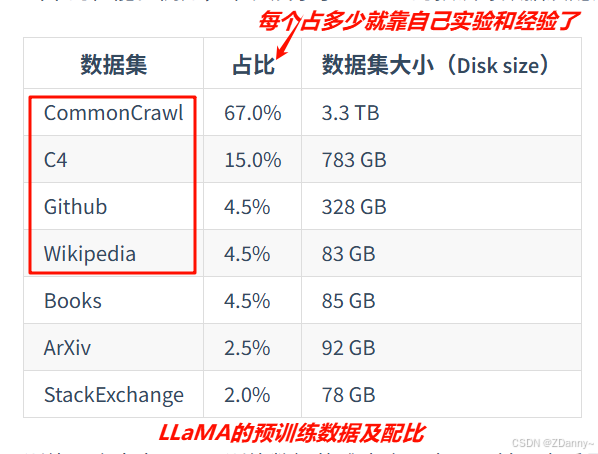
**数据内容的质量 > 数量**
目前有已处理好的语料和用来处理语料的框架,就是有帮你处理的工具和处理好的。
如:[627B Slimpajama 数据集](https://huggingface.co/datasets/cerebras/SlimPajama-627B/tree/main/train)、[1T 的 RedPajama数据集](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T)
*怎么自己弄数据集?*
| 环节 | 主要内容 | 方法与说明 |
|------------|--------------------------------------------------------------------------|----------------------------------------------------------------------------|
| ①文档准备 | - 爬取
- URL 过滤
- 文档提取
- 语言选择等 | 数据预处理的第一步,保证基础语料来源合法、可用 |
| ②语料过滤 | - 基于模型的方法:训练文本分类器进行过滤
- 基于启发式的方法:人工定义质量指标 | 提升语料质量,去除低质量、不相关或噪声数据 |
| ③语料去重 | - 基于 Hash 算法:计算相似性并去除
- 基于子串匹配:精确去重 | 避免重复语料,提升模型泛化能力,减少冗余 |
---
#### LLM 参数量和训练资源的拉扯
LLM一般都在多卡分布式GPU集群训
要用**分布式框架**对数据、中间参数、参数切分。
- 训练资源:`卡(数量、类型) + 时间`
| 参数量 | 训练资源 | 训练时长 |
|--------|----------|----------|
| **1B** | 约 256 张 A100 | 2 ~ 3 天 |
| **10B** | 约 1024 张 A100 | 30+ 天 |
---
#### LLM 的分卡训怎么训
> *什么是分布式训练框架?*
> 卡上存参数(模型并行),数据分卡训(数据并行)
> 框架就是让开发者更方便运用不同的分布式方法的。
> 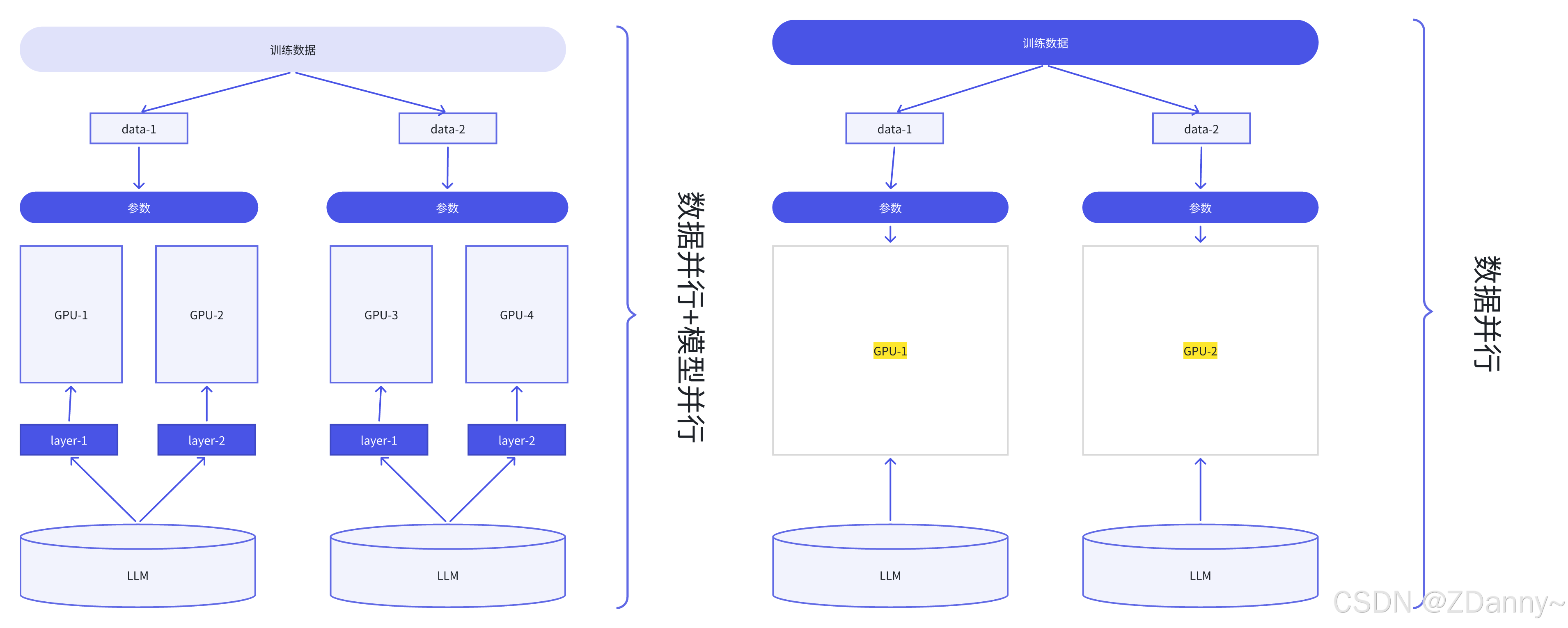
| 常见的分布式方式? | 说明 | 常见的分布式框架 ?|
|------------------|------|------------------|
| **数据并行 (Data Parallel, DP)** | 每个 GPU 训练相同模型副本,不同数据切分,梯度同步更新 | PyTorch DDP, Horovod |
| **张量并行 (Tensor Parallel, TP)** | 将单层模型的参数(矩阵)切分到多个 GPU 上并行计算 | Megatron-LM, ColossalAI |
| **流水线并行 (Pipeline Parallel, PP)** | 将模型层切分到不同 GPU,分批次流水线执行 | GPipe, Megatron-LM |
| **3D 并行 (DP + TP + PP)** | 同时结合数据并行、张量并行和流水线并行,提升扩展性 | Megatron-LM |
| **ZeRO (Zero Redundancy Optimizer)零冗余优化器** | 将优化器状态、梯度、参数切分到不同 GPU,减少显存占用 | DeepSpeed (挺广的)|
| **异构并行 (Heterogeneous Parallel)** | 同时利用 GPU、CPU、TPU 等不同设备协作 | ColossalAI, Ray |
拓展:Deepspeed框架=核心策略:ZeRO+CPU-offload
> ZeRO
> - 数据并行(分数据到不同卡)+ 显存优化(优化计算时单卡的显存占用)
> - 训练时单卡的显存占用是什么样的?
> - 模型状态占用的显存:模型参数、模型梯度和优化器 Adam 的状态参数。 ☞ 1M参数量 -- 混合精度训练下 --16M显存(12M的Adam状态参数)
> - 剩余状态占用的显存:包括激活值、各种缓存和显存碎片
>
>
> 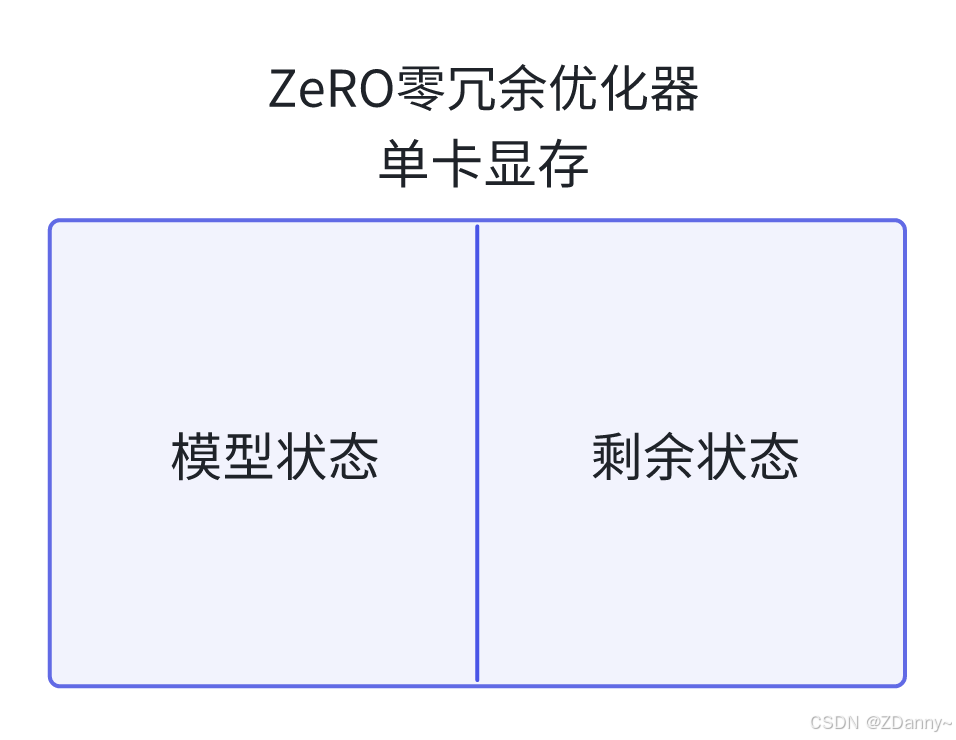
>可以发现Adam的状态参数占用很大,所以ZeRO就针对这个问题给出了一些优化策略。
> - *ZeRO给的优化策略是什么?*
> 分片,但分的越细,合并时通信开销就大
